
INDICE
La diffusione in molti settori dei sistemi di Machine Learning basati su algoritmi ha portato alla luce il problema della responsabilità per i danni da “algoritmo difettoso”.
I sistemi di apprendimento automatico basati su algoritmi consentono infatti alle macchine di migliorare le proprie prestazioni nel tempo; in caso di errore, però, le conseguenze per le persone e le cose possono essere particolarmente gravi. La complessità di questi sistemi rende però difficile capire chi può essere chiamato a rispondere per questi danni.
La risposta, come vedremo, non è scontata e nemmeno univoca.
Il rapporto tra sistemi di “apprendimento automatico” e responsabilità rappresenta oggi uno degli aspetti più intriganti e problematici del settore dell’Intelligenza Artificiale, sempre più diffusa anche in Italia. Per comprenderne il perché è necessario capire anzitutto cosa s’intende per “apprendimento automatico” e quali sono le difficoltà nell’individuale una “responsabilità da Machine Learning”.
Apprendimento automatico: conosciamolo meglio
Alzi la mano chi ha sentito pronunciare le parole “Machine Learning” e “algoritmo” almeno una volta.
Bene.
Ora alzi la mano chi saprebbe darne una definizione soddisfacente.
In questo caso il numero di mani alzate sarà decisamente più basso.
Tale incertezza dipende dal fatto che spesso questi termini sono utilizzati in maniera ambigua, o dandone per scontato il significato.
Nel tentativo di fare chiarezza, potremmo definire il Machine Learning (“apprendimento automatico” in italiano) come:
“una branca dell’intelligenza artificiale (…) che utilizza metodi statistici per migliorare la performance di un algoritmo nell’identificare pattern nei dati. Nell’ambito dell’informatica, l’apprendimento automatico è una variante alla programmazione tradizionale nella quale in una macchina si predispone l’abilità di apprendere qualcosa dai dati in maniera autonoma, senza istruzioni esplicite” (Voce “apprendimento automatico” in Wikipedia).
Nell’accezione tradizionale informatica, invece, l’algoritmo è:
“una sequenza finita di operazioni elementari, eseguibili facilmente da un elaboratore che, a partire da un insieme di dati I (input), produce un altro insieme di dati O (output) che soddisfano un preassegnato insieme di requisiti” (Voce “algoritmo” in Enciclopedia Treccani).
Lo scopo dei sistemi di apprendimento automatico basati su algoritmi è quello di consentire alle macchine di eseguire determinati compiti in maniera sempre più efficiente “imparando dai propri errori”.
Inizialmente, il sistema viene addestrato a compiere un’attività partendo da un set di dati stabilito (input). Nel tempo, l’algoritmo di learning modifica i parametri iniziali sulla base dei risultati ottenuti e li migliora.
In sostanza, grazie all’autoapprendimento e alla raccolta di dati, la macchina perfeziona via via la propria capacità di agire o di assumere decisioni. In questo modo, la risposta data (output) al problema iniziale sarà sempre più accurata e precisa.
Per questa ragione sono definite macchine “intelligenti” o “razionali”, in quanto capaci di scegliere la migliore risposta o azione da compiere per raggiungere un dato obiettivo.
Tipologie di apprendimento automatico
I sistemi di Machine Learning possono essere distinti in base alla metodologia di apprendimento utilizzata. Si distingue tra:
- apprendimento supervisionato (supervised learning), in cui l’addestramento della macchina è effettuato a partire da modelli esemplificativi di input e output inseriti in un database.
Qui la macchina non è soggetta a vere e proprie regole di condotta. Al contrario, sono previsti meri modelli esemplificativi che l’elaboratore potrà analizzare per scegliere l’azione migliore da eseguire in ipotesi non ancora previste.
In questi casi la discrezionalità della macchina è limitata perché sia l’input che l’output sono “preconfezionati”. - apprendimento non supervisionato (unsupervised learning), in cui il sistema informatico non ha a disposizione output La macchina deve scegliere autonomamente la risposta da dare ad uno specifico problema sulla base dei dati forniti (input). Le informazioni raccolte nel tempo sono catalogate per somiglianze e/o differenze e poi utilizzate dal sistema per migliorare le proprie prestazioni.
Esempi di apprendimento non supervisionato sono i motori di ricerca come Google o Yahoo.
In questi casi l’output non è prestabilito, essendo il risultato dell’esperienza e dell’autoapprendimento della macchina. Questo pone notevoli problemi in tema di trasparenza dei processi algoritmici e di responsabilità in ipotesi di danno. - apprendimento per rinforzo (reinforcement learning) in cui la macchina assume decisioni e agisce in maniera indipendente, interagendo con l’ambiente circostante. La risposta (output) è modulata su ciò che accade intorno al sistema stesso. Per fare ciò, la macchina viene dotata di strumenti di interazione quali videocamere, sensori o dispositivi gps. Un esempio di apprendimento per rinforzo è quello delle automobili a guida autonoma o “self-driving”, o quelli per il controllo della produttività dei dipendenti di cui abbiamo parlato anche in un precedente articolo.
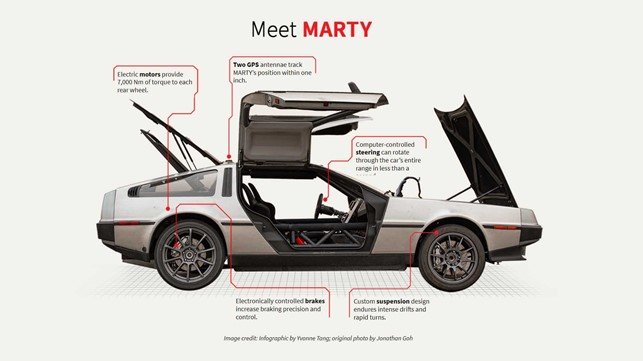
Un esempio di sistema Machine Learning: Marty di Ritorno al Futuro, una DeLorean del 1981 trasformata in self-driving car elettrica. Center for Automotive Research – Stanford University
In ciascuna delle ipotesi sopra citate, la capacità decisionale della macchina è regolata da algoritmi che stabiliscono la risposta o l’azione migliore da compiere per eseguire un certo compito.
Ma cosa accade quando l’algoritmo sbaglia?
Quando la macchina sbaglia: le regole sulla responsabilità nel Machine Learning
I sistemi di Machine Learning mantengono un certo grado di “discrezionalità” nella scelta dell’azione da compiere per risolvere il problema dato. Come detto, ciò si verifica soprattutto nei sistemi di unsupervised learning in cui l’output è il risultato dell’esperienza e dell’autoapprendimento della macchina.
Questo pone delicati problemi in tema di “responsabilità da Machine Learning”. Infatti, se il sistema automatizzato assumesse una decisione sulla base di dati incompleti o errati oppure, a causa di un malfunzionamento dovuto a un errore di sistema, causasse danni a cose o persone chi dovrebbe risponderne? La macchina – e quindi l’algoritmo – oppure i soggetti che li hanno progettati, addestrati e commercializzati?
Il problema è certamente complesso.
Ad oggi non esistono disposizioni specifiche in tema di responsabilità per danni derivanti dall’utilizzo di macchine intelligenti.
Gli interpreti hanno cercato di “colmare il vuoto” applicando anche in queste ipotesi le norme già esistenti in materia di responsabilità del produttore, equiparando i sistemi di apprendimento automatico a “prodotti”.
Ciò ha permesso di estendere anche a questo settore la legislazione europea in materia di sicurezza dei prodotti (Direttiva 01/95/CE) e di vendita e garanzie dei beni di consumo (Direttiva 99/44/CE), la quale prevede una responsabilità oggettiva (che prescinde dal dolo o dalla colpa) in capo al produttore.
Allo stato, quindi, il fabbricante della macchina intelligente è il soggetto chiamato a rispondere degli eventuali danni causati dall’algoritmo.
Questa soluzione però non soddisfa del tutto.
A differenza di quanto accade in caso di beni materiali, in ipotesi di sistemi di intelligenza artificiale il “produttore” non è sempre in grado di prevedere quali saranno i futuri sviluppi dell’algoritmo di learning, in quanto frutto dell’autoapprendimento di quest’ultimo.
Inoltre, i danni causati dalle macchine “intelligenti” potrebbero non dipendere dall’architettura con cui i sistemi sono stati progettati, bensì dal modo in cui sono stati “addestrati” dagli utilizzatori finali, ad esempio a causa della cattiva qualità dei dati con cui sono stati alimentati.
Verso un “danno da algoritmo”?
Se questo è lo stato dell’arte, l’utilizzo di algoritmi sempre più sofisticati consentirà ben presto alle macchine intelligenti di assumere decisioni imperscrutabili per l’uomo.
Già ora si parla di “modello black box” per indicare quei sistemi che possono essere descritti nei loro comportamenti esterni ma il cui funzionamento interno – ossia il processo che ha condotto agli output – non è comprensibile.
I sistemi di Machine Learning, in quanto programmati per l’autoapprendimento, ben presto assumeranno decisioni ed eseguiranno tasks in maniera totalmente indipendente. Le azioni delle macchine “intelligenti” non saranno più prevedibili dall’uomo e il potere di controllo di quest’ultimo andrà via via riducendosi.
Come potrebbe allora il produttore essere chiamato a rispondere degli eventuali danni provocati dalla macchina “intelligente”, se quest’ultima sfugge totalmente al suo controllo?
Sarebbe più corretto ipotizzare una responsabilità del sistema di autoapprendimento e quindi dell’algoritmo.
L’esigenza di introdurre una legislazione nuova, idonea a disciplinare gli aspetti critici della questione relativa al “danno da algoritmo” è avvertita anche dalle Istituzioni europee. Queste ultime hanno annunciato per il 2021 l’adozione di un regolamento specifico in materia.
In vista di tale intervento, il Parlamento europeo ha approvato lo scorso 20 ottobre 2020 una Risoluzione recante raccomandazioni alla Commissione europea sul regime di responsabilità civile per l’intelligenza artificiale (A9-0178/2020).
Il Machine Learning ci riguarda!
Non dobbiamo pensare che i sistemi di apprendimento automatico appartengano unicamente ai settori della ricerca scientifica, dell’industria 4.0, della medicina o dei mercati finanziari. Il Machine Learning è presente anche nelle nostre case o negli smartphone che utilizziamo ed è ormai parte integrante della nostra quotidianità.
Non ci credete?
Pensate agli smart speakers come Google home o Alexa, dispositivi “intelligenti” capaci di interagire con le persone e l’ambiente circostante. Questi oggetti possono compiere una serie di attività quali fornire informazioni, riprodurre musica, inviare comandi ad altri dispositivi smart presenti nell’abitazione o effettuare acquisti online. Il comando vocale dato dall’utente (“Ok Google” oppure “Alexa” seguito dal comando o dalla richiesta) viene “tradotto” dallo smart speaker in una sequenza di bit e successivamente eseguito.
Anche gli assistenti virtuali per smartphone come Siri (per sistemi iOS) o Cortana (per sistemi Windows e Android) o i sempre più diffusi chatbot eseguono ordini, rispondono a domande, suggeriscono prodotti o itinerari e interagiscono con le app scaricate sul dispositivo.
Ulteriori applicazioni del Machine Learning riguardano i sistemi di traduzione automatica come Google traduttore o Microsoft Translator, i filtri anti-spam delle caselle di posta elettronica e i sistemi di raccomandazione integrati in piattaforme di intrattenimento come Spotify o Netflix.
Anche nel settore pubblico, questa tecnologia si sta diffondendo. Ad esempio, cominciano ad essere installati su ampia scala sistemi pubblici di videosorveglianza basati sul riconoscimento facciale (ne abbiamo parlato anche in questo articolo).
Infine, che dire dell’utilizzo di sistemi di Intelligenza Artificiale in ambito business?
La scelta del candidato ideale per un posto di lavoro vacante (ne parliamo anche in questo articolo), la decisione di concedere un mutuo a un correntista o di ottimizzare i premi delle polizze assicurative costituiscono attività rimesse perlopiù agli algoritmi, con notevoli conseguenze, peraltro, sul piano della parità di trattamento. Oppure pensiamo all’utilizzo dell’intelligenza artificiale negli studi professionali o nelle aziende. Il danno che può essere causato in questi ipotesi può essere molto elevato: per questo è importante capire su chi ricade la responsabilità per il malfunzionamento del sistema di Machine Learning.
In ciascuna delle ipotesi citate, i software apprendono e perfezionano le proprie risposte sulla base dei dati raccolti nel tempo, senza la necessità di alcun intervento umano ulteriore. Anche in questi casi potremmo assistere a eventi dannosi riconducibili sul piano causale agli algoritmi di autoapprendimento.
La sensazione è che la partita della responsabilità del Machine Learning per “danno da algoritmo” sia appena iniziata, ed il legislatore dovrà arrivare presto a colmare il vuoto legislativo.







